
Two Towers
Contents
Two Towers¶
The two-tower model learns to represent two items of various types (such as user profiles, search queries, web documents, answer passages, or images) in the same vector space, so that similar or related items are close to each other. These two items are referred to as the query and candidate object, since when paired with a nearest neighbour search service such as Vertex Matching Engine, the two-tower model can retrieve candidate objects related to an input query object. These objects are encoded by a query and candidate encoder (the two “towers”) respectively, which are trained on pairs of relevant items.
Since we wish to retrieve financial entities related to each other, we have the query item as the business description in plain text and the candidate item as the CIK ticker and its SIC category description of the financial entity.
Training Data¶
Training data consists of query document and candidate document pairs. It is needed to provide only positive pairs, where the query and candidate documents are considered a match. Training with negative pairs or partial matches is not supported.
We used the 2018 filings of companies descriptions from the top 5 categories (Prepackaged Software, Pharmaceutical Preparations, Crude Petroleum and Natural Gas, Real Estate Investment Trusts, State Commercial Banks) to train our model. Filings from multiple years for each company is used so that the model has a better understanding of each company and its relevant descriptions.
Structure of a single record in the training data:
{
"query":
{
"description": x["coDescription"]
},
"candidate":
{
"financial_entity": x["CIK"],
"category" : x["SIC_desc"]
}
}
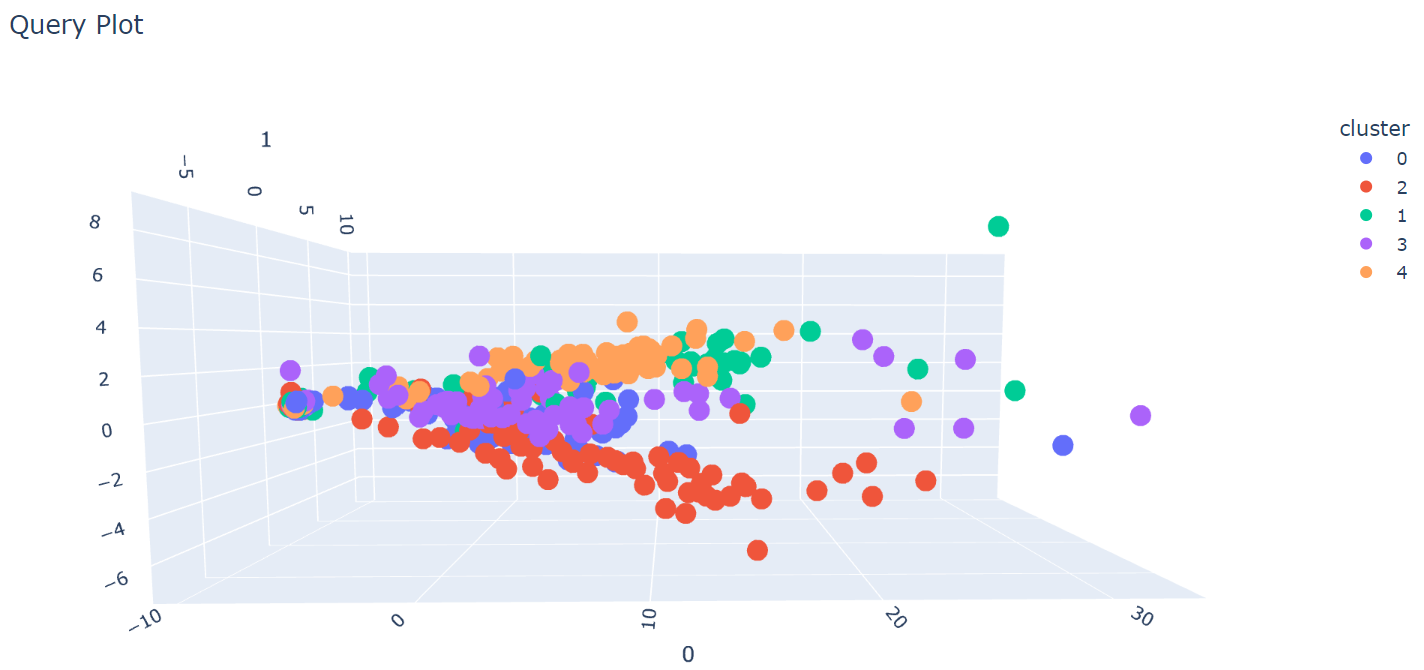
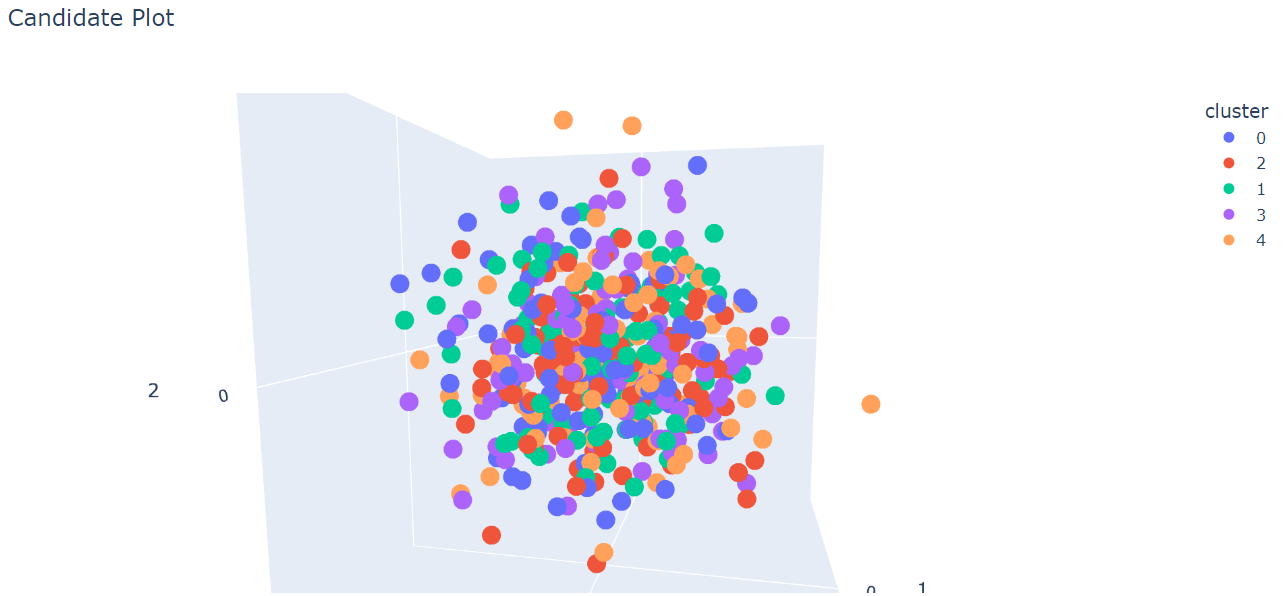
Results¶
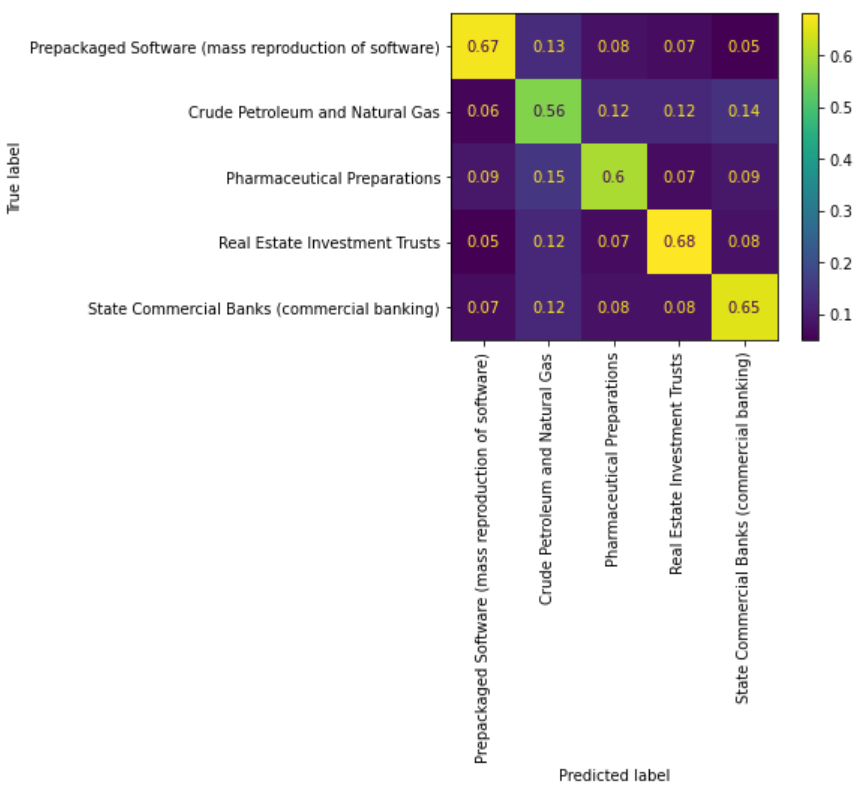
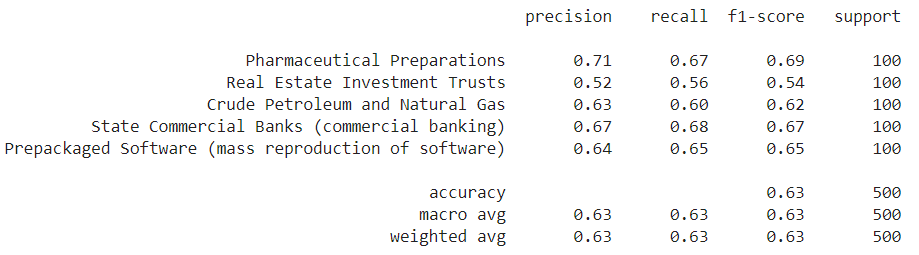
From the confusion matrix and the classification report, we can conclude that the Two Tower model does not do a good job at classfying the category of the companies compared to the other models. We believe this is due to the nature of our data as there are only a hand-full of “positive” pairs of query objects(10k report description) and candidate objects(company ID & category). With a large set of data but very few pairs of data, it is difficult for the model to create an embedding space where related items are close together. This is also apparent by looking at the 3D candidate embeddings generated using PCA.