
Doc2Vec
Contents
Doc2Vec¶
A continuation of using neural networks to help predict company embeddings, we now explore doc2vec.
This works much in the same was as Word2Vec, except on input we also specify which document/filing a given word has come from, resulting in ready made document vectors for us.
Lets get to the code!¶
First we need to load in the functions and data:
import os
import json
import pandas as pd
import numpy as np
import sys
sys.path.insert(0, '..')
%load_ext autoreload
%autoreload 2
%aimport std_func
# Hide warnings
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("../data/preprocessed.csv")
Thanks to the gensim package, it’s quite easy to implement doc2vec.
from gensim.models import doc2vec
from collections import namedtuple
docs = []
analyzedDocument = namedtuple('AnalyzedDocument', 'words tags')
for i, text in enumerate(df["coDescription_stopwords"]):
words = text.lower().split()
tags = [i]
docs.append(analyzedDocument(words, tags))
model = doc2vec.Doc2Vec(docs, vector_size = 100, window = 10, min_count = 1, workers = 4)
Like Word2Vec, we now also have a document vector matrix. We specified only 100 dimensions due to computational limitations, and the fact anymore most likely would not have helped. (Tune the hyper-parameter later)
And here we have the vectors for each company.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1.069693 | 0.178045 | -1.494915 | 1.975032 | 0.821181 | -0.237772 | -0.952073 | -0.296611 | -3.084478 | -1.059440 | ... | -0.373738 | -1.569935 | -3.687043 | 0.155367 | 0.716785 | -0.532835 | -0.148241 | 2.769564 | -0.610424 | -1.721455 |
| 1 | 0.576653 | -1.412108 | -2.440013 | 2.347250 | 0.058851 | 0.432892 | -0.617848 | -0.992708 | -1.153835 | 0.419545 | ... | -1.235869 | -0.771894 | -2.954011 | -0.232072 | -0.430426 | -0.326765 | -0.040944 | 0.135734 | 0.554869 | -1.329786 |
| 2 | -1.158351 | -0.213180 | -2.251126 | 2.846082 | 0.778042 | 0.325837 | -0.533828 | -0.531405 | -3.166338 | -0.376345 | ... | -0.097557 | 0.173748 | -4.151709 | 1.077599 | -0.321112 | 0.823240 | -2.134309 | 0.777602 | 1.781383 | -4.190876 |
| 3 | 0.042752 | 0.426476 | -1.134072 | 1.108936 | -0.686854 | -0.832317 | -0.604564 | -0.258482 | -1.826194 | -0.151843 | ... | -1.789804 | -2.944545 | -2.614629 | -1.172493 | -1.010654 | 0.851054 | -0.698927 | 1.539879 | 1.511696 | -1.148776 |
| 4 | -1.723339 | -2.885207 | -2.834879 | 2.373493 | -1.766554 | 0.772403 | -1.874856 | 2.813653 | -1.315448 | 1.487623 | ... | -3.770599 | 1.020818 | -4.491113 | 2.180514 | 3.247819 | 2.867793 | -0.491228 | 2.126635 | -3.065429 | -2.985566 |
5 rows × 100 columns
Plotting the results¶
Here are the results of the doc2vec semantic company embedding after dimensionality reduction using PCA.
These look great! It seems doc2vec was able to create embeddings for our companies that separated them by industry very well, even after the PCA dimensionality reduction.
Performance Evaluation¶
conf_mat = std_func.conf_mat(doc_vec_2,df)
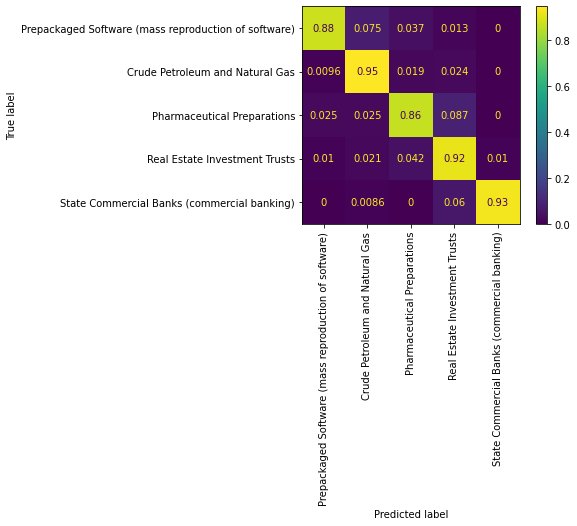
dot_product_df, accuracy, cm = std_func.dot_product(doc_vec_2,df)
from sklearn.metrics import classification_report
print(classification_report(dot_product_df["y_true"], dot_product_df["y_pred"], target_names=df["SIC_desc"].unique()))
precision recall f1-score support
Prepackaged Software (mass reproduction of software) 0.92 0.88 0.90 80
Crude Petroleum and Natural Gas 0.94 0.95 0.94 208
Pharmaceutical Preparations 0.82 0.86 0.84 80
Real Estate Investment Trusts 0.90 0.92 0.91 191
State Commercial Banks (commercial banking) 0.98 0.93 0.96 116
accuracy 0.92 675
macro avg 0.91 0.91 0.91 675
weighted avg 0.92 0.92 0.92 675
From the confusion matrix and the classification report, we can conclude that the doc2vec company embedding does a great job at classifying the category of the companies. This is in line with our observations of the PCA plots, as they did a very good job at separating companies in different industries.