
Word2vec
Contents
Word2vec¶
Another method to find company embeddings is to use word2vec. How it works and how we aim to use is explained below.
How it works¶
Imagine I have two sentences:
“Formula One driver Lewis Hamilton is a seven time world champion”.
“Ferrari driver Sebastian Vettel fails to qualify for the fifth Grand Prix in a row”
Say I want find words that are semantically related to Lewis.
In word2vec we can use two different algorithms, continuous bag of words (CBOW) and skip-gram negative sampling.
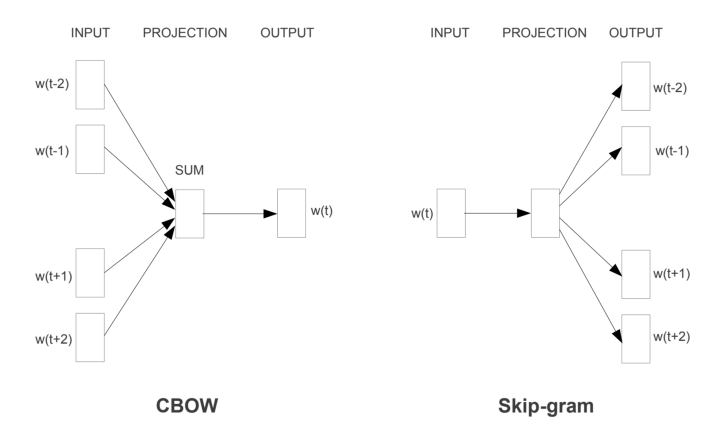
Continuous bag of words (CBOW)¶
We take a window of n words surrounding “Lewis” and use those words as input into a neural network, using the logic that if certains words appear together often, then they’re most likely semantically related. We take these surrounding words and plug them into a neural network to train weights which predict “Lewis”.
We plug in a one hot vector for each word in the window and train the hidden layer to output probabilities of the current word (“Lewis”). Therefore the order of the words do not matter, just what the words are.
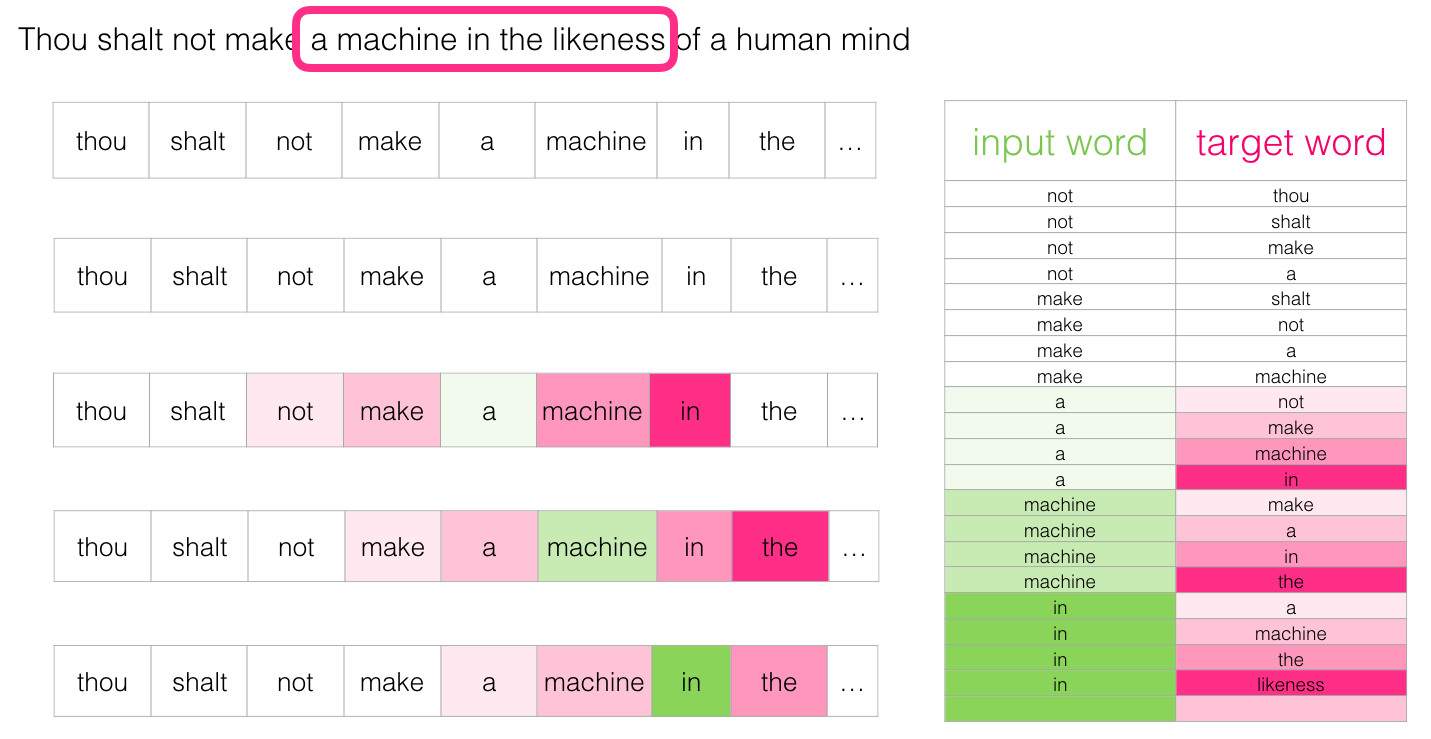
Skip Gram Negative Sampling¶
Whereas, in the second option of using the continuous skip-gram architecture; the model uses the current word to predict the surrounding window of context words. The skip-gram architecture weighs nearby context words more heavily than more distant context words. The output probabilities are going to relate to how likely it is to find each vocabulary word near our input word. For example, if you gave the trained network the input word “Europe”, the output probabilities are going to be much higher for words like “Belgium” and “Continent” than for unrelated words like “fruits” and “cats”.
How we will use it¶
We will first run all the words in each annual report through the word2vec neural network in order to extract a matrix of word embeddings, where each word is theoretically close to semantically related words. We then take a subset of these word embeddings of only words that belong in a given company filing, and average them. This produces a pseudo-document vector which theoretically represents these companies semantically.
Lets get to the code!¶
First we need to load in the functions and data:
import os
import json
import pandas as pd
import numpy as np
import sys
sys.path.insert(0, '..')
%load_ext autoreload
%autoreload 2
%aimport std_func
# Hide warnings
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("../data/preprocessed.csv")
Here we split each document converted into word vectors.
from gensim.models.word2vec import Word2Vec
from gensim import utils
bd_processed = df["coDescription_stopwords"].apply(lambda x: utils.simple_preprocess(x))
bd_processed.head()
0 [mongodb, leading, modern, general, purpose, d...
1 [salesforce, global, leader, customer, relatio...
2 [splunk, provides, innovative, software, solut...
3 [okta, leading, independent, provider, identit...
4 [veeva, leading, provider, industry, cloud, so...
Name: coDescription_stopwords, dtype: object
Now lets build the Word2Vec model! Due to the sheer amount of computation required, we will limit wach word vector produced to just 200 dimensions. Studies have shown that increasing this size beyond 200 - 300 does not bring much measurable benefit.
model_w = Word2Vec(bd_processed, vector_size=200)
We can examine words and see which words are most similar. Below are the most similar words to cloud, trial, and oil.
model_w.wv.most_similar(positive =['cloud'], topn = 5)
[('computing', 0.8458328247070312),
('server', 0.8364641666412354),
('architecture', 0.8308152556419373),
('saas', 0.8282819390296936),
('analytics', 0.8199993968009949)]
model_w.wv.most_similar(positive =['trial'], topn = 5)
[('study', 0.8036917448043823),
('clinicaltrials', 0.697586715221405),
('clinicaltrial', 0.6807914972305298),
('superiority', 0.665607213973999),
('trialin', 0.6298800706863403)]
model_w.wv.most_similar(positive =['oil'], topn = 5)
[('oiland', 0.6403454542160034),
('natural', 0.622684895992279),
('flared', 0.6089735627174377),
('extractive', 0.5805891156196594),
('greenhouse', 0.5653460025787354)]
Now we’ll map these word vectors back to each document, by averaging all the word vectors that belong to words in a given document (filing)
def doc_to_vec(text):
word_vecs = [model_w.wv[w] for w in text if w in model_w.wv]
if len(word_vecs) == 0:
return np.zeros(model_w.vector_size)
return np.mean(word_vecs, axis = 0)
doc_vec = pd.DataFrame(bd_processed.apply(doc_to_vec).tolist())
labels = np.asarray(model_w.wv.index_to_key)
If you’re interested, the entire 200 dimensions of each document is below:
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 190 | 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.159033 | 0.055967 | 0.014864 | -0.297311 | 0.067456 | 0.282759 | -0.040386 | -0.427278 | 0.148376 | -0.340623 | ... | -0.304856 | 0.266816 | -0.216066 | -0.008328 | -0.068407 | -0.437028 | -0.476530 | -0.176278 | 0.247398 | 0.264209 |
| 1 | -0.140404 | 0.077223 | 0.001257 | -0.392737 | 0.093251 | 0.265769 | -0.056022 | -0.511015 | 0.213310 | -0.447720 | ... | -0.299677 | 0.205178 | -0.229327 | -0.092090 | -0.056792 | -0.522980 | -0.601174 | -0.204188 | 0.253022 | 0.275649 |
| 2 | -0.142740 | -0.060063 | -0.076419 | -0.306981 | 0.128802 | 0.221056 | -0.046773 | -0.409091 | 0.312673 | -0.372047 | ... | -0.334398 | 0.288147 | -0.153633 | -0.024609 | -0.135258 | -0.371083 | -0.539743 | -0.082908 | 0.265215 | 0.285849 |
| 3 | -0.133720 | 0.070401 | -0.031563 | -0.307723 | 0.242843 | 0.334700 | -0.119261 | -0.390896 | 0.253073 | -0.330773 | ... | -0.398048 | 0.142708 | -0.252419 | 0.061319 | -0.180680 | -0.413864 | -0.614312 | -0.132485 | 0.202475 | 0.411073 |
| 4 | 0.014422 | -0.237138 | -0.186225 | -0.143008 | 0.166273 | 0.028883 | -0.281006 | -0.249900 | 0.204903 | -0.516946 | ... | -0.130443 | 0.143876 | 0.002484 | -0.071151 | -0.142258 | -0.300688 | -0.508855 | -0.480292 | 0.102527 | 0.200002 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 670 | 0.111148 | -0.054346 | -0.203614 | -0.097918 | 0.357645 | 0.046136 | -0.125623 | -0.277637 | 0.043418 | -0.853734 | ... | -0.180901 | 0.150282 | 0.135340 | 0.161292 | -0.129060 | -0.525148 | -0.470147 | -0.575567 | 0.354022 | 0.093391 |
| 671 | -0.203535 | -0.055653 | 0.082146 | 0.354123 | 0.126121 | -0.072692 | -0.009743 | -0.119472 | -0.020538 | 0.292816 | ... | 0.063492 | 0.065280 | -0.479574 | -0.126391 | -0.159675 | -0.080301 | 0.030360 | -0.204595 | 0.339216 | 0.078881 |
| 672 | 0.131316 | -0.472236 | -0.365607 | -0.183405 | 0.175830 | -0.181948 | -0.356068 | -0.032695 | 0.182481 | -0.422719 | ... | -0.213269 | 0.253307 | 0.044226 | 0.052528 | -0.142184 | -0.249127 | -0.348137 | -0.584525 | 0.063504 | 0.151148 |
| 673 | -0.112617 | -0.095615 | -0.053283 | 0.008728 | 0.329610 | -0.193568 | -0.060199 | -0.236820 | 0.098372 | -0.605420 | ... | -0.140800 | 0.121511 | 0.190697 | -0.049923 | -0.147480 | -0.331960 | -0.522371 | -0.468938 | 0.278566 | 0.186633 |
| 674 | -0.121182 | 0.033752 | 0.079671 | -0.423486 | -0.011810 | 0.181291 | -0.021053 | -0.507927 | 0.273670 | -0.468184 | ... | -0.320344 | 0.262449 | -0.124172 | -0.143327 | -0.066496 | -0.376354 | -0.475029 | -0.067517 | 0.062258 | 0.217689 |
675 rows × 200 columns
Plotting the results¶
Here are the results of the word2vec semantic company embedding after dimensionality reduction using PCA.
conf_mat = std_func.conf_mat(tfidf,df)conf_mat = std_func.conf_mat(tfidf,df)As you can see, these company embeddings don’t like quite that great in our reduced space. Perhaps they didn’t capture the semantic meaning very well, or its accurate and the semantic embedding of many companies is very jumbled up and their industry classification isn’t entirely correct.
Performance Evaluation¶
conf_mat = std_func.conf_mat(doc_vec,df)
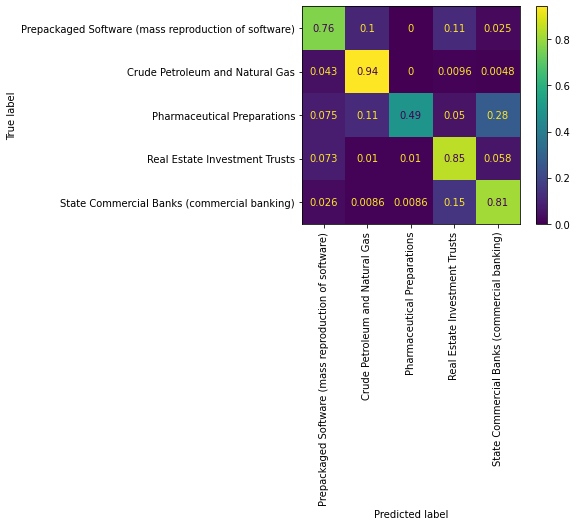
dot_product_df, accuracy, cm = std_func.dot_product(doc_vec,df)
from sklearn.metrics import classification_report
print(classification_report(dot_product_df["y_true"], dot_product_df["y_pred"], target_names=df["SIC_desc"].unique()))
precision recall f1-score support
Prepackaged Software (mass reproduction of software) 0.66 0.76 0.71 80
Crude Petroleum and Natural Gas 0.91 0.94 0.92 208
Pharmaceutical Preparations 0.93 0.49 0.64 80
Real Estate Investment Trusts 0.84 0.85 0.84 191
State Commercial Banks (commercial banking) 0.72 0.81 0.76 116
accuracy 0.82 675
macro avg 0.81 0.77 0.77 675
weighted avg 0.83 0.82 0.81 675
From the confusion matrix and the classification report, we can conclude that the word2vec pseudo-company embedding does a poor job at classifying the category of the companies, except for the Crude Petroleum. This is in line with our observations of the PCA plots, as they did not do a very good job at separating companies in different industries.