
Word embedding using tf-idf matrices
Contents
Word embedding using tf-idf matrices¶
This notebook explores using tf-idf matrices to create these company embeddings.
Tf-Idf stands for term frequency - inverse document frequency. Each row in this matrix represents one document (in this case, one annaul report of a given company) and each column represents a word (or a sequence of words called an n-gram, like “University of Toronto”).
A term frequency matrix has the count of occurences of a given word for each document, while a tf-idf matrix performs a transformation on that term frequency matrix. The computation for each cell is as follows:
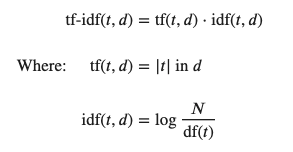
Where t is the current term we are process, and d is the current document we are looking in
Where N is the total number of documents in the document set and df(t) is the document frequency of t;
The document frequency is the number of documents in the document set that contain the term t
^ From sklearn
Why do we do this?
The purpose of a tf-idf transformation is give more importance to words that occur less frequently among all the documents. Common terms among financial documents like these could contain “financial” or “business” but they don’t provide any extra information to help us identify what makes a given company unique. tf-idf augments the term counts by giving higher weights to terms that are less common within the collection of documents but mentioned frequently in one document, implying these terms make this document special.
We’ll be training two models from sklearn’s feature_extraction, first using a CountVectorizer to obtain term-frequencies of terms of size 2-4 (we do this as some terms such as “cloud computing” carry more meaning than those words do separately. We also only select the top 600 words by freqeuncy as the columns.
The result is then piped into a TfidfTransformer, augmenting the values so the values more accurately represent the importance of a given term.
import pandas as pd
import numpy as np
import sys
sys.path.insert(0, '..')
%load_ext autoreload
%autoreload 2
%aimport std_func
# Hide warnings
import warnings
warnings.filterwarnings("ignore")
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.pipeline import Pipeline
df = pd.read_csv("../data/preprocessed.csv")
pipe = Pipeline([('count', CountVectorizer(ngram_range = (2,4),
stop_words = 'english', max_features = 600)),
('tfidf', TfidfTransformer())]).fit(df["coDescription_stopwords"])
Here are some of the terms we are left with after passing all our documents through the CountVectorizer and TfidfTransformer.
feature_names = pd.DataFrame(pipe['count'].get_feature_names_out())
feature_names.sample(5)
| 0 | |
|---|---|
| 504 | reserve ratio |
| 448 | product development |
| 330 | limit ability |
| 277 | gene therapy |
| 7 | adequately capitalized |
As you can see below, the matrix is quite sparse since some companies don’t contain any occurrences of some terms.
# The tf-idf matrix
tfidf = pd.DataFrame(pipe.transform(df["coDescription_stopwords"]).toarray())
tfidf.head()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 590 | 591 | 592 | 593 | 594 | 595 | 596 | 597 | 598 | 599 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.142196 | 0.159010 | 0.0 | 0.000000 |
| 1 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.0 | 0.000000 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| 2 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.030074 | 0.000000 | 0.068363 | 0.0 | 0.000000 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.000000 |
| 3 | 0.0 | 0.000000 | 0.0 | 0.000000 | 0.000000 | 0.000000 | 0.059925 | 0.0 | 0.000000 | 0.000000 | ... | 0.0 | 0.0 | 0.000000 | 0.000000 | 0.0 | 0.0 | 0.070304 | 0.047170 | 0.0 | 0.000000 |
| 4 | 0.0 | 0.037094 | 0.0 | 0.002481 | 0.006809 | 0.010094 | 0.001935 | 0.0 | 0.010972 | 0.009869 | ... | 0.0 | 0.0 | 0.050738 | 0.010656 | 0.0 | 0.0 | 0.000000 | 0.155342 | 0.0 | 0.011082 |
5 rows × 600 columns
This is a 2D PCA reduction of that 600 dimensional space. We’re plotting the first two dimensions, which capture the most variance.
And this is a 3-dimensional plot which plots the first three dimensions. You can interact with it as well.
We can see from the above PCA plot of the first three dimensions that there are clearly terms which certain industries are more drawn toward. Unfortunately, the Real Estate and Software industries still seem quite closely clustered.
We can look at the explained variance of each dimension the PCA embedding of our tf-idf matrix produced below:
# From the explained variance ratio, we see that the top three dimensions don't actually explain that much of the variation that exists within our data/companies.
plot[0].explained_variance_ratio_
array([0.1203797 , 0.09021696, 0.06845749, 0.03556207, 0.01948634,
0.01886276, 0.01732033, 0.016957 , 0.0168748 , 0.0157679 ])
And the total variance explained by the top three dimensions:
plot[0].explained_variance_ratio_[0:3].sum()
0.27905414951961593
Based on the above, the top three principle components only explain 27.9% of the total variance that exists within the data.
If you’d like to analyze how much a given term contributes to each of the 10 dimensions, please see the DataFrame hidden below:
| (ability make,) | (accounting standard,) | (acquire property,) | (act act,) | (act amended,) | (additional capital,) | (additional information,) | (adequately capitalized,) | (adverse effect,) | (adverse effect business,) | ... | (vice president,) | (volcker rule,) | (wa million,) | (weighted average,) | (wholly owned,) | (wholly owned subsidiary,) | (wide range,) | (year ended,) | (year ended december,) | (year year,) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.008464 | 0.003215 | 0.009458 | 0.014314 | 0.009306 | 0.006414 | -0.009847 | 0.022502 | -0.003787 | -0.000597 | ... | 0.003886 | 0.023861 | 0.006737 | 0.011844 | 0.001967 | 0.001536 | -0.001609 | 0.007127 | 0.009542 | 0.002051 |
| 1 | -0.006914 | -0.001608 | -0.033876 | 0.014038 | 0.002999 | -0.001260 | -0.000087 | 0.021544 | -0.018656 | -0.008920 | ... | -0.007964 | 0.024241 | -0.004846 | -0.017862 | -0.005544 | -0.003738 | 0.005211 | -0.059814 | -0.058013 | -0.000887 |
| 2 | -0.008100 | -0.000819 | -0.033001 | 0.001018 | -0.007243 | -0.001871 | -0.012349 | 0.002899 | 0.004780 | -0.003369 | ... | -0.012004 | 0.004508 | -0.008028 | -0.019714 | -0.010987 | -0.007323 | -0.003155 | -0.040893 | -0.039873 | -0.005463 |
| 3 | -0.010786 | 0.013262 | -0.047523 | 0.002819 | 0.018005 | 0.001505 | 0.016095 | -0.001664 | -0.003365 | 0.003747 | ... | 0.084738 | -0.000753 | 0.013445 | -0.022549 | 0.004597 | 0.006836 | 0.049065 | 0.057272 | 0.028712 | 0.010855 |
| 4 | -0.006102 | 0.006359 | -0.025227 | -0.006558 | -0.012304 | 0.001315 | -0.030749 | -0.003130 | -0.039120 | -0.024943 | ... | -0.010316 | -0.002412 | -0.014154 | -0.002825 | -0.017007 | -0.014696 | -0.010613 | -0.038709 | -0.041894 | -0.005550 |
| 5 | 0.002518 | 0.030172 | 0.007068 | 0.003646 | -0.009230 | 0.014216 | 0.007443 | -0.001798 | 0.016553 | 0.005776 | ... | -0.101164 | -0.001603 | 0.002698 | 0.006645 | 0.015213 | 0.014740 | -0.021836 | 0.072585 | 0.067995 | 0.008810 |
| 6 | 0.005507 | -0.023193 | -0.019887 | 0.000187 | 0.000646 | -0.002336 | 0.016841 | -0.000746 | 0.037932 | 0.012265 | ... | -0.046518 | 0.003691 | -0.023651 | -0.007327 | -0.007194 | -0.010799 | -0.001660 | -0.114059 | -0.102341 | -0.004366 |
| 7 | 0.000905 | -0.005792 | -0.037019 | -0.005573 | -0.003105 | -0.006360 | -0.001132 | 0.000403 | -0.025049 | -0.017461 | ... | 0.010307 | -0.012295 | 0.018167 | 0.006456 | -0.019083 | -0.016132 | 0.008781 | 0.013286 | 0.026005 | 0.014090 |
| 8 | 0.006890 | -0.005548 | -0.008503 | 0.003195 | 0.015146 | 0.002359 | 0.012220 | 0.001388 | 0.053269 | 0.020224 | ... | -0.090039 | -0.002921 | -0.003572 | -0.015149 | -0.006047 | -0.005661 | -0.000944 | -0.050482 | -0.049346 | -0.003859 |
| 9 | -0.010636 | -0.008363 | 0.043205 | -0.004026 | 0.011528 | -0.009786 | -0.024494 | -0.000946 | -0.040907 | -0.021747 | ... | 0.105559 | -0.004188 | -0.010354 | -0.027281 | 0.011025 | 0.016220 | 0.015216 | -0.107320 | -0.116302 | -0.008063 |
10 rows × 600 columns
And finally, this DataFrame is sorted by the amount each term contributes to the first dimension, which captures the most variance in our data. This tells us that the largest variations/spread of companies along the x axis in the 2D PCA plot measures how much a company has to with with Oil & Gas, or real estate.
components.abs().sort_values(2, axis = 1, ascending = False)
| (natural gas,) | (oil natural,) | (oil natural gas,) | (real estate,) | (oil gas,) | (hydraulic fracturing,) | (operating partnership,) | (proved reserve,) | (square foot,) | (joint venture,) | ... | (asset le,) | (condition result operation,) | (operation financial,) | (prior approval,) | (result operation,) | (deferred tax asset,) | (financial condition result operation,) | (federal state law,) | (credit agreement,) | (gain loss,) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.002005 | 0.001982 | 0.001937 | 0.188639 | 0.000110 | 0.000673 | 0.026153 | 0.000259 | 0.018317 | 0.017743 | ... | 0.021999 | 0.011730 | 0.002284 | 0.014785 | 0.012128 | 0.010725 | 0.011656 | 0.009905 | 0.000852 | 0.005947 |
| 1 | 0.196597 | 0.125686 | 0.123456 | 0.214145 | 0.099522 | 0.045112 | 0.115532 | 0.034217 | 0.092581 | 0.092607 | ... | 0.018273 | 0.016138 | 0.006959 | 0.015385 | 0.029917 | 0.003795 | 0.016080 | 0.011678 | 0.015433 | 0.004754 |
| 2 | 0.562633 | 0.361787 | 0.355658 | 0.322306 | 0.242208 | 0.126237 | 0.102704 | 0.094673 | 0.090834 | 0.087948 | ... | 0.000407 | 0.000367 | 0.000360 | 0.000193 | 0.000186 | 0.000185 | 0.000169 | 0.000157 | 0.000135 | 0.000076 |
| 3 | 0.155039 | 0.106771 | 0.105380 | 0.409966 | 0.010175 | 0.028908 | 0.103406 | 0.022930 | 0.058630 | 0.082272 | ... | 0.005541 | 0.004569 | 0.004581 | 0.001488 | 0.006424 | 0.007491 | 0.004128 | 0.000546 | 0.000928 | 0.000118 |
| 4 | 0.175973 | 0.131838 | 0.130225 | 0.307324 | 0.136522 | 0.013898 | 0.048052 | 0.015385 | 0.006324 | 0.026444 | ... | 0.003965 | 0.007490 | 0.018909 | 0.009662 | 0.019792 | 0.023773 | 0.008009 | 0.016728 | 0.003803 | 0.012466 |
| 5 | 0.095364 | 0.076487 | 0.076699 | 0.156055 | 0.179790 | 0.003669 | 0.081142 | 0.000015 | 0.175806 | 0.032846 | ... | 0.002977 | 0.025164 | 0.006759 | 0.007885 | 0.044086 | 0.055872 | 0.025241 | 0.009560 | 0.036170 | 0.019073 |
| 6 | 0.110037 | 0.112524 | 0.111102 | 0.086845 | 0.316979 | 0.037661 | 0.166196 | 0.003459 | 0.173090 | 0.027158 | ... | 0.002407 | 0.035747 | 0.000003 | 0.000960 | 0.030747 | 0.031767 | 0.035388 | 0.002353 | 0.001867 | 0.012426 |
| 7 | 0.017848 | 0.024331 | 0.025931 | 0.125901 | 0.203296 | 0.018955 | 0.240440 | 0.002552 | 0.161714 | 0.142819 | ... | 0.010650 | 0.015529 | 0.003892 | 0.011129 | 0.000705 | 0.000673 | 0.015026 | 0.005019 | 0.007116 | 0.007545 |
| 8 | 0.073394 | 0.102255 | 0.102129 | 0.104266 | 0.457320 | 0.060742 | 0.115657 | 0.012562 | 0.159311 | 0.047621 | ... | 0.005138 | 0.075166 | 0.015021 | 0.001682 | 0.079298 | 0.018498 | 0.074569 | 0.007705 | 0.011313 | 0.008324 |
| 9 | 0.051696 | 0.071149 | 0.073272 | 0.179297 | 0.389438 | 0.035030 | 0.135676 | 0.007491 | 0.141683 | 0.009063 | ... | 0.003423 | 0.045098 | 0.018155 | 0.002528 | 0.066920 | 0.038007 | 0.045096 | 0.001955 | 0.059955 | 0.022602 |
10 rows × 600 columns
Performance Evaluation¶
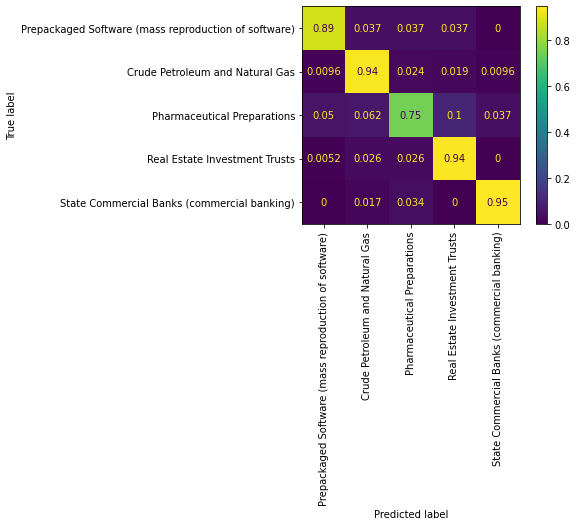
conf_mat = std_func.conf_mat(tfidf,df)
dot_product_df, accuracy, cm = std_func.dot_product(tfidf,df)
from sklearn.metrics import classification_report
print(classification_report(dot_product_df["y_true"], dot_product_df["y_pred"], target_names=df["SIC_desc"].unique()))
precision recall f1-score support
Prepackaged Software (mass reproduction of software) 0.91 0.89 0.90 80
Crude Petroleum and Natural Gas 0.93 0.94 0.93 208
Pharmaceutical Preparations 0.78 0.75 0.76 80
Real Estate Investment Trusts 0.92 0.94 0.93 191
State Commercial Banks (commercial banking) 0.96 0.95 0.95 116
accuracy 0.91 675
macro avg 0.90 0.89 0.90 675
weighted avg 0.91 0.91 0.91 675
From the confusion matrix and the classification report, we can conclude that the tf-idf company embedding does a good job overall at classifying the category of the companies, except for the Pharmaceutical industry. More specifically, this model is best at classifying companies in the Commerical Banking industry.